Assumptions¶
Hardware and software environments¶
No assumptions on a specific hardware environment are made. It must be possible to create an array library adhering to this standard that runs (efficiently) on a variety of different hardware: CPUs with different architectures, GPUs, distributed systems and TPUs and other emerging accelerators.
The same applies to software environments: it must be possible to create an array library adhering to this standard that runs efficiently independent of what compilers, build-time or run-time execution environment, or distribution and install method is employed. Parallel execution, JIT compilation, and delayed (lazy) evaluation must all be possible.
The variety of hardware and software environments puts constraints on choices made in the API standard. For example, JIT compilers may require output dtypes of functions to be predictable from input dtypes only rather than input values.
Dependencies¶
The only dependency that’s assumed in this standard is that on Python itself. Python >= 3.8 is assumed, motivated by the use of positional-only parameters (see function and method signatures).
Importantly, array libraries are not assumed to be aware of each other, or of a common array-specific layer. The use cases do not require such a dependency, and building and evolving an array library is easier without such a coupling. Facilitation support of multiple array types in downstream libraries is an important use case however, the assumed dependency structure for that is:
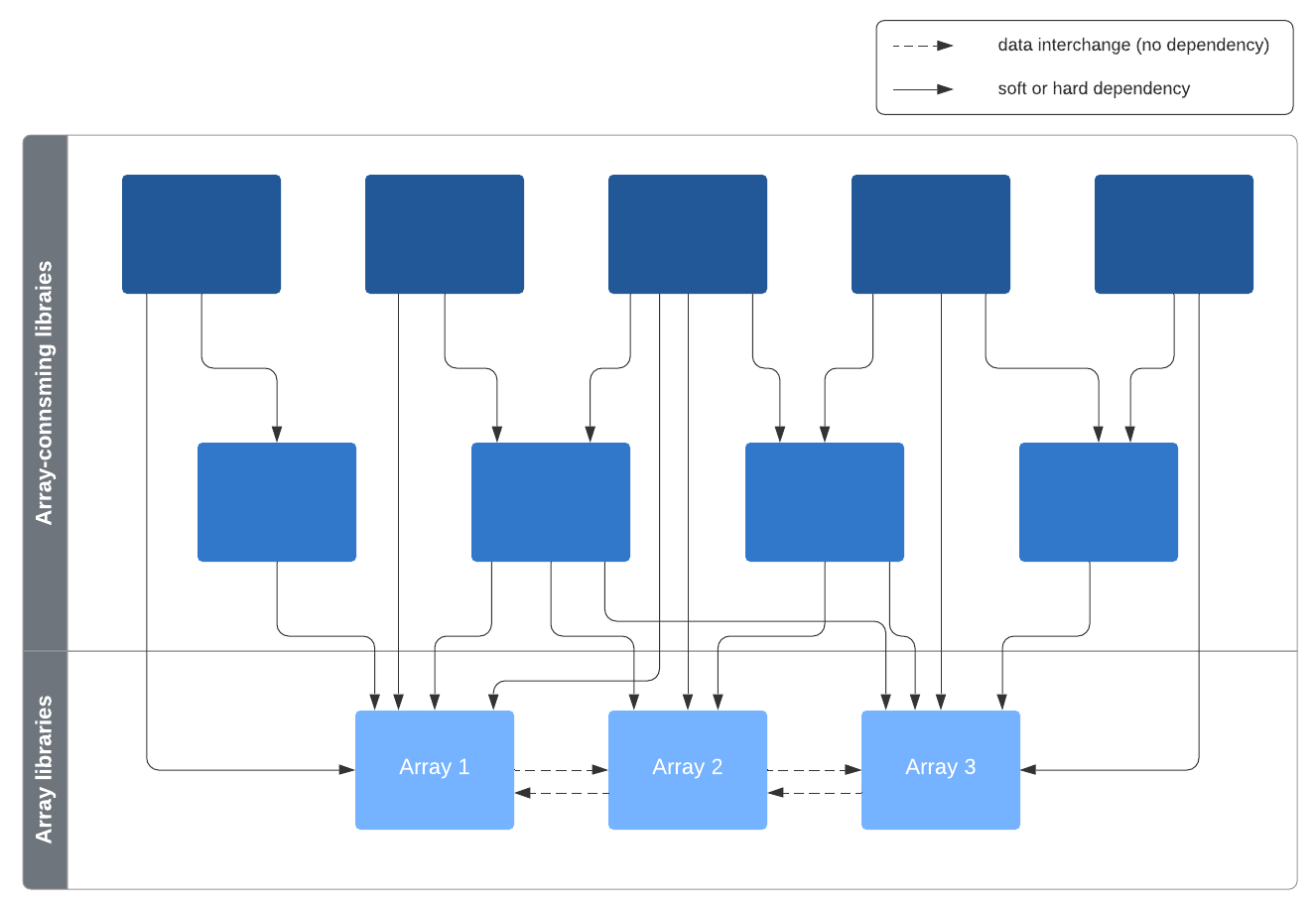
Array libraries may know how to interoperate with each other, for example by constructing their own array type from that of another library or by shared memory use of an array (see Data interchange mechanisms). This can be done without a dependency though - only adherence to a protocol is enough.
Array-consuming libraries will have to depend on one or more array libraries.
That could be a “soft dependency” though, meaning retrieving an array library
namespace from array instances that are passed in, but not explicitly doing
import arraylib_name.
Backwards compatibility¶
The assumption made during creation of this standard is that libraries are constrained by backwards compatibility guarantees to their users, and are likely unwilling to make significant backwards-incompatible changes for the purpose of conforming to this standard. Therefore it is assumed that the standard will be made available in a new namespace within each library, or the library will provide a way to retrieve a module or module-like object that adheres to this standard. See How to adopt this API for more details.
Production code & interactive use¶
It is assumed that the primary use case is writing production code, for example in array-consuming libraries. As a consequence, making it easy to ensure that code is written as intended and has unambiguous semantics is preferred - and clear exceptions must be raised otherwise.
It is also assumed that this does not significantly detract from the interactive user experience. However, in case existing libraries differ in behavior, the more strict version of that behavior is typically preferred. A good example is array inputs to functions - while NumPy accepts lists, tuples, generators, and anything else that could be turned into an array, most other libraries only accept their own array types. This standard follows the latter choice. It is likely always possible to put a thin “interactive use convenience layer” on top of a more strict behavior.