Purpose and scope¶
Introduction¶
Python users have a wealth of choice for libraries and frameworks for numerical computing, data science, machine learning, and deep learning. New frameworks pushing forward the state of the art in these fields are appearing every year. One unintended consequence of all this activity and creativity has been fragmentation in multidimensional array (a.k.a. tensor) libraries - which are the fundamental data structure for these fields. Choices include NumPy, Tensorflow, PyTorch, Dask, JAX, CuPy, MXNet, Xarray, and others.
The APIs of each of these libraries are largely similar, but with enough differences that it’s quite difficult to write code that works with multiple (or all) of these libraries. This array API standard aims to address that issue, by specifying an API for the most common ways arrays are constructed and used.
Why not simply pick an existing API and bless that as the standard? In short, because there are often good reasons for the current inconsistencies between libraries. The most obvious candidate for that existing API is NumPy. However NumPy was not designed with non-CPU devices, graph-based libraries, or JIT compilers in mind. Other libraries often deviate from NumPy for good (necessary) reasons. Choices made in this API standard are often the same ones NumPy makes, or close to it, but are different where necessary to make sure all existing array libraries can adopt this API.
This API standard¶
This document aims to standardize functionality that exists in most/all array libraries and either is commonly used or is needed for consistency/completeness. Usage is determined via analysis of downstream libraries, see Usage Data. An example of consistency is: there are functional equivalents for all Python operators (including the rarely used ones).
Beyond usage and consistency, there’s a set of use cases that inform the API design to ensure it’s fit for a wide range of users and situations - see Use cases.
A question that may arise when reading this document is: “what about functionality that’s not present in this document? This:
means that there is no guarantee the functionality is present in libraries adhering to the standard
does not mean that that functionality is unimportant
may indicate that that functionality, if present in a particular array library, is unlikely to be present in all other libraries
History¶
The first library for numerical and scientific computing in Python was Numeric, developed in the mid-1990s. In the early 2000s a second, similar library, Numarray, was created. In 2005 NumPy was written, superceding both Numeric and Numarray and resolving the fragmentation at that time. For roughly a decade, NumPy was the only widely used array library. Over the past ~5 years, mainly due to the emergence of new hardware and the rise of deep learning, many other libraries have appeared, leading to more severe fragmentation. Concepts and APIs in newer libraries were often inspired by (or copied from) those in older ones - and then changed or improved upon to fit new needs and use cases. Individual library authors discussed ideas, however there was never (before this array API standard) a serious attempt to coordinate between all libraries to avoid fragmentation and arrive at a common API standard.
The idea for this array API standard grew gradually out of many conversations between maintainers during 2019-2020. It quickly became clear that any attempt to write a new “reference library” to fix the current fragmentation was infeasible - unlike in 2005, there are now too many different use cases and too many stakeholders, and the speed of innovation is too high. In May 2020 an initial group of maintainers was assembled in the Consortium for Python Data API Standards to start drafting a specification for an array API that could be adopted by each of the existing array and tensor libraries. That resulted in this document, describing that API.
Scope (includes out-of-scope / non-goals)¶
This section outlines what is in scope and out of scope for this API standard.
In scope¶
The scope of the array API standard includes:
Functionality which needs to be included in an array library for it to adhere to this standard.
Names of functions, methods, classes and other objects.
Function signatures, including type annotations.
Semantics of functions and methods. I.e. expected outputs including precision for and dtypes of numerical results.
Semantics in the presence of
nan’s,inf’s, empty arrays (i.e. arrays including one or more dimensions of size0).Casting rules, broadcasting, indexing
Data interchange. I.e. protocols to convert one type of array into another type, potentially sharing memory.
Device support.
Furthermore, meta-topics included in this standard include:
Use cases for the API standard and assumptions made in it
API standard adoption
API standard versioning
Future API standard evolution
Array library and API standard versioning
Verification of API standard conformance
The concrete set of functionality that is in scope for this version of the standard is shown in this diagram:
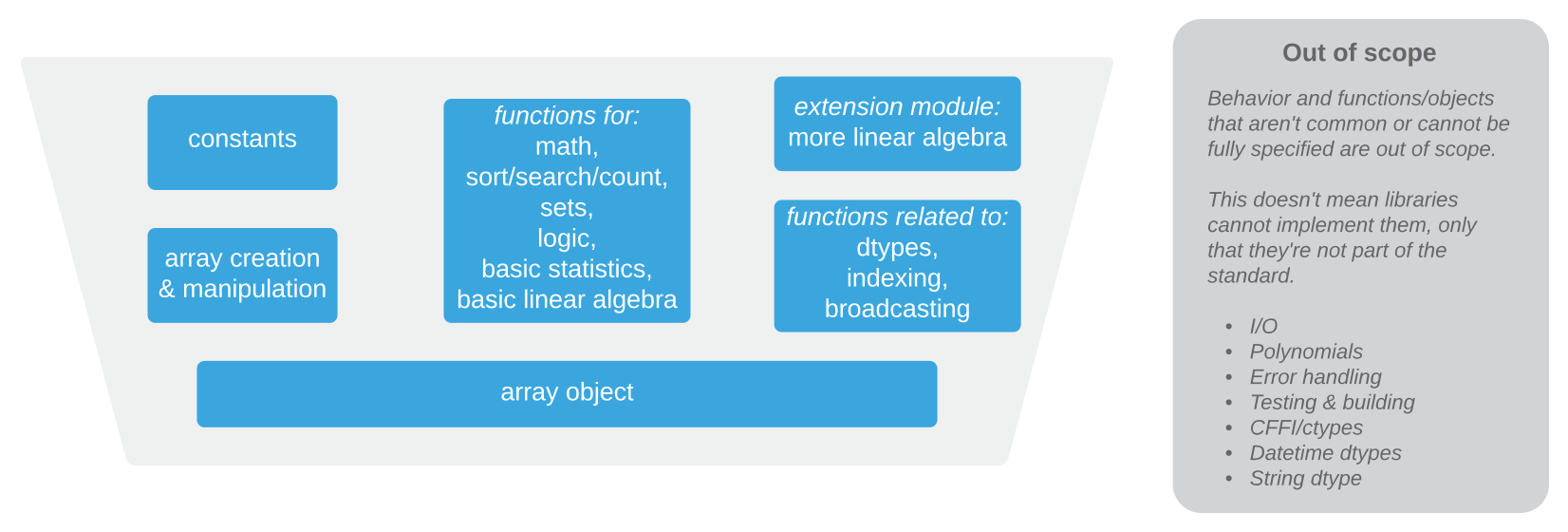
Goals for the API standard include:
Make it possible for array-consuming libraries to start using multiple types of arrays as inputs.
Enable more sharing and reuse of code built on top of the core functionality in the API standard.
For authors of new array libraries, provide a concrete API that can be adopted as is, rather than each author having to decide what to borrow from where and where to deviate.
Make the learning curve for users less steep when they switch from one array library to another one.
Out of scope¶
Implementations of the standard are out of scope.
Rationale: the standard will consist of a document and an accompanying test suite with which the conformance of an implementation can be verified. Actual implementations will live in array libraries; no reference implementation is planned.
Execution semantics are out of scope. This includes single-threaded vs. parallel execution, task scheduling and synchronization, eager vs. delayed evaluation, performance characteristics of a particular implementation of the standard, and other such topics.
Rationale: execution is the domain of implementations. Attempting to specify execution behavior in a standard is likely to require much more fine-grained coordination between developers of implementations, and hence is likely to become an obstacle to adoption.
Non-Python API standardization (e.g., Cython or NumPy C APIs)
Rationale: this is an important topic for some array-consuming libraries, but there is no widely shared C/Cython API and hence it doesn’t make sense at this point in time to standardize anything. See the C API section for more details.
Standardization of these dtypes is out of scope: bfloat16, extended precision floating point, datetime, string, object and void dtypes.
Rationale: these dtypes aren’t uniformly supported, and their inclusion at this point in time could put a significant implementation burden on libraries. It is expected that some of these dtypes - in particular
bfloat16- will be included in a future version of the standard.The following topics are out of scope: I/O, polynomials, error handling, testing routines, building and packaging related functionality, methods of binding compiled code (e.g.,
cffi,ctypes), subclassing of an array class, masked arrays, and missing data.Rationale: these topics are not core functionality for an array library, and/or are too tied to implementation details.
NumPy (generalized) universal functions, i.e. ufuncs and gufuncs.
Rationale: these are NumPy-specific concepts, and are mostly just a particular way of building regular functions with a few extra methods/properties.
Behaviour for unexpected/invalid input to functions and methods.
Rationale: there are a huge amount of ways in which users can provide invalid or unspecified input to functionality in the standard. Exception types or other resulting behaviour cannot be completely covered and would be hard to make consistent between libraries.
Non-goals for the API standard include:
Making array libraries identical so they can be merged.
Each library will keep having its own particular strength, whether it’s offering functionality beyond what’s in the standard, performance advantages for a given use case, specific hardware or software environment support, or more.
Implement a backend or runtime switching system to be able to switch from one array library to another with a single setting or line of code.
This may be feasible, however it’s assumed that when an array-consuming library switches from one array type to another, some testing and possibly code adjustment for performance or other reasons may be needed.
Making it possible to mix multiple array libraries in function calls.
Most array libraries do not know about other libraries, and the functions they implement may try to convert “foreign” input, or raise an exception. This behaviour is hard to specify; ensuring only a single array type is used is best left to the end user.
Implications of in/out of scope¶
If something is out of scope and therefore will not be part of (the current version of) the API standard, that means that there are no guarantees that that functionality works the same way, or even exists at all, across the set of array libraries that conform to the standard. It does not imply that this functionality is less important or should not be used.
Stakeholders¶
Arrays are fundamental to scientific computing, data science, and machine learning and deep learning. Hence there are many stakeholders for an array API standard. The direct stakeholders of this standard are authors/maintainers of Python array libraries. There are many more types of indirect stakeholders though, including:
maintainers of libraries and other programs which depend on array libraries (called “array-consuming libraries” in the rest of this document)
authors of non-Python array libraries
developers of compilers and runtimes with array-specific functionality
end users
Libraries that are being actively considered - in terms of current behaviour and API surface - during the creation of the first version of this standard include:
Other Python array libraries that are currently under active development and could adopt this API standard include:
There are a huge amount of array-consuming libraries; some of the most prominent ones that are being taken into account - in terms of current array API usage or impact of design decisions on them - include (this list is likely to grow it over time):
Array libraries in other languages, some of which may grow a Python API in the future or have taken inspiration from NumPy or other array libraries, include:
Xtensor (C++, cross-language)
XND (C, cross-language)
stdlib (JavaScript)
rust-ndarray (Rust)
rray (R)
ND4J (JVM)
NumSharp (C#)
Compilers, runtimes, and dispatching layers for which this API standard may be relevant:
How to read this document¶
For guidance on how to read and understand the type annotations included in this specification, consult the Python documentation.
How to adopt this API¶
Most (all) existing array libraries will find something in this API standard that is incompatible with a current implementation, and that they cannot change due to backwards compatibility concerns. Therefore we expect that each of those libraries will want to offer a standard-compliant API in a new namespace. The question then becomes: how does a user access this namespace?
The simplest method is: document the import to use to directly access the
namespace (e.g. import package_name.array_api). This has two issues though:
Array-consuming libraries that want to support multiple array libraries then have to explicitly import each library.
It is difficult to version the array API standard implementation (see Versioning).
To address both issues, a uniform way must be provided by a conforming implementation to access the API namespace, namely a method on the array object:
xp = x.__array_namespace__()
The method must take one keyword, api_version=None, to make it possible to
request a specific API version:
xp = x.__array_namespace__(api_version='2020.10')
The xp namespace must contain all functionality specified in
API specification. The namespace may contain other functionality; however,
including additional functionality is not recommended as doing so may hinder
portability and inter-operation of array libraries within user code.
Checking an array object for Compliance¶
Array-consuming libraries are likely to want a mechanism for determining
whether a provided array is specification compliant. The recommended approach
to check for compliance is by checking whether an array object has an
__array_namespace__ attribute, as this is the one distinguishing feature of
an array-compliant object.
Checking for an __array_namespace__ attribute can be implemented as a small
utility function similar to the following.
def is_array_api_obj(x):
return hasattr(x, '__array_namespace__')
Note
Providing a “reference library” on which people depend is out-of-scope for
the standard. Hence the standard cannot, e.g., provide an array ABC from
which libraries can inherit to enable an isinstance check. However, note
that the numpy.array_api implementation aims to provide a reference
implementation with only the behavior specified in this standard - it may
prove useful for verifying one is writing portable code.
Discoverability of conforming implementations¶
It may be useful to have a way to discover all packages in a Python environment which provide a conforming array API implementation, and the namespace that that implementation resides in. To assist array-consuming libraries which need to create arrays originating from multiple conforming array implementations, or developers who want to perform for example cross-library testing, libraries may provide an entry point in order to make an array API namespace discoverable.
Optional feature
Given that entry points typically require build system & package installer specific implementation, this standard chooses to recommend rather than mandate providing an entry point.
The following code is an example for how one can discover installed conforming libraries:
from importlib.metadata import entry_points
try:
eps = entry_points()['array_api']
ep = next(ep for ep in eps if ep.name == 'package_name')
except TypeError:
# The dict interface for entry_points() is deprecated in py3.10,
# supplanted by a new select interface.
ep = entry_points(group='array_api', name='package_name')
xp = ep.load()
An entry point must have the following properties:
group: equal to
array_api.name: equal to the package name.
object reference: equal to the array API namespace import path.
Conformance¶
A conforming implementation of the array API standard must provide and support all the functions, arguments, data types, syntax, and semantics described in this specification.
A conforming implementation of the array API standard may provide additional features (e.g., values, objects, properties, data types, functions, and function arguments) beyond those described in this specification.
Libraries which aim to provide a conforming implementation but haven’t yet completed such an implementation may, and are encouraged to, provide details on the level of (non-)conformance. For details on how to do this, see Verification - measuring conformance.
Normative References¶
The following referenced documents are indispensable for the application of this specification.
IEEE 754-2019: IEEE Standard for Floating-Point Arithmetic. Institute of Electrical and Electronic Engineers, New York (2019).
Scott Bradner. 1997. “Key words for use in RFCs to Indicate Requirement Levels”. RFC 2119. doi:10.17487/rfc2119.